Understanding Hawked Server Status
October 26, 2024Hawked Server Status refers to the operational state of a server being monitored by the Hawked process monitoring and restarting tool. Hawked is a lightweight and versatile utility commonly used in Linux environments to ensure the high availability of critical applications and services. By continuously monitoring server status, Hawked can automatically detect failures, crashes, or unresponsiveness, and take appropriate actions to restore services and minimize downtime.
 Hawked server monitoring dashboard
Hawked server monitoring dashboard
Deciphering Hawked Server Status Codes
Hawked employs a simple yet effective status code system to represent the current state of a monitored server. Understanding these codes is crucial for system administrators to quickly assess the health of their servers and diagnose potential issues. Here’s a breakdown of the common Hawked server status codes:
- Starting: This status indicates that Hawked has initiated the process of starting the server, but it is not yet fully operational.
- Running: A server displaying a “Running” status signifies that it is online, functioning correctly, and responding to requests as expected.
- Failed: The “Failed” status denotes that Hawked has detected a problem with the server. This could be due to a crash, unresponsiveness, or exceeding defined resource limits.
- Stopped: When a server is intentionally shut down or halted by Hawked due to repeated failures, it enters the “Stopped” state.
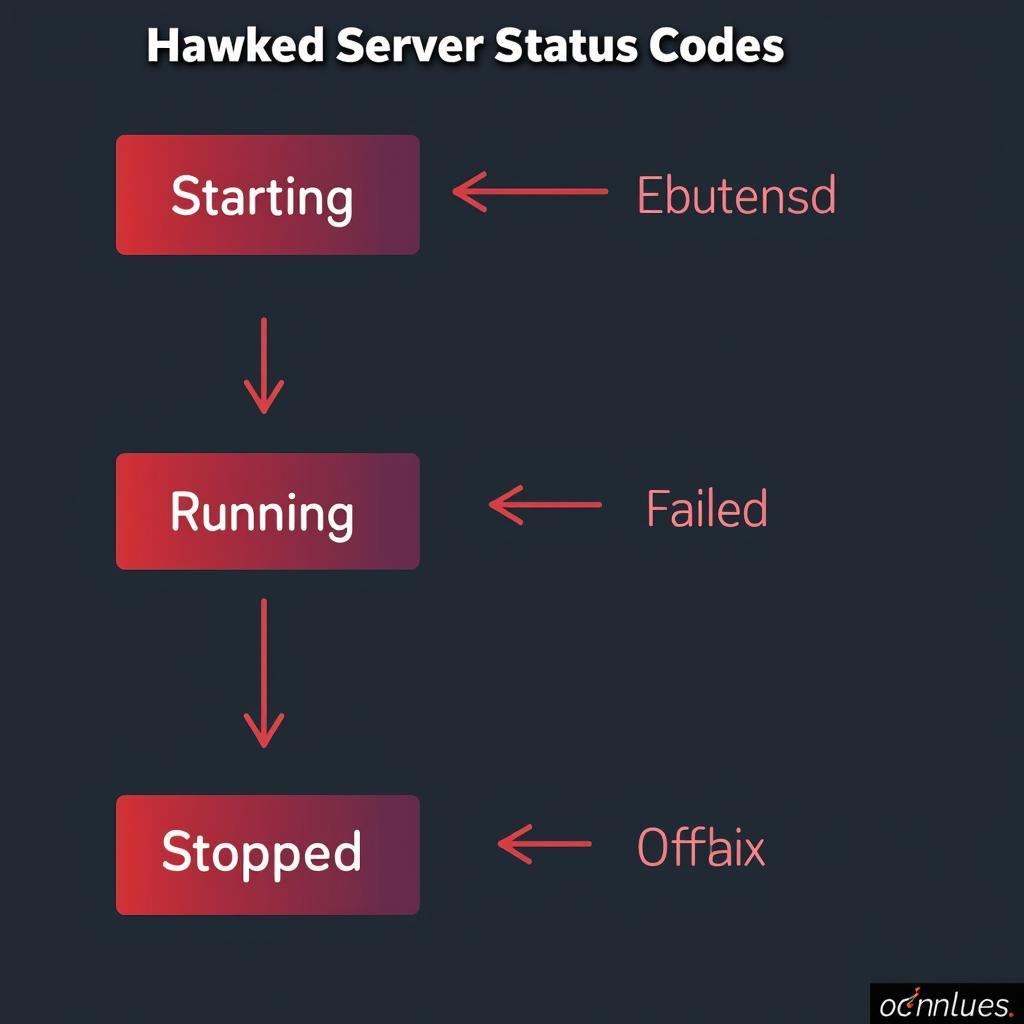 Visual representation of Hawked server status codes
Visual representation of Hawked server status codes
Common Causes of Hawked Server Status Changes
Several factors can influence the status of a server monitored by Hawked. Identifying the root cause of a status change is essential for effective troubleshooting and remediation. Let’s delve into some common culprits behind Hawked server status fluctuations:
- Application Errors: Bugs or exceptions within the application itself can lead to crashes or unresponsiveness, triggering a “Failed” status in Hawked.
- Resource Exhaustion: Depletion of system resources like CPU, memory, or disk space can overwhelm the server, causing performance degradation or complete failure.
- Network Connectivity Issues: Interruptions or instability in network connections can disrupt communication between the Hawked monitor and the server, leading to inaccurate status reporting.
- Hardware Failures: Malfunctions in server hardware components such as hard drives, RAM, or power supplies can result in unexpected shutdowns or unavailability.
Best Practices for Maintaining Optimal Hawked Server Status
To ensure the continuous availability and reliability of servers managed by Hawked, adhering to best practices is paramount. Implementing these recommendations can significantly reduce the likelihood of server downtime and streamline troubleshooting efforts.
- Proactive Monitoring and Alerting: Configure Hawked to send timely alerts via email, SMS, or integrated monitoring systems upon detecting server status changes or exceeding predefined thresholds.
- Comprehensive Logging: Enable detailed logging within both Hawked and the monitored application to capture valuable information for diagnosing issues and understanding the sequence of events leading to failures.
- Resource Optimization: Regularly analyze server resource utilization patterns and optimize application code and configurations to prevent resource bottlenecks and improve overall performance.
- Automated Recovery Mechanisms: Implement automated scripts or procedures within Hawked to attempt service restarts, failover to redundant instances, or notify administrators for manual intervention in case of persistent failures.
By incorporating these best practices and understanding the nuances of Hawked server status, system administrators can proactively manage their server infrastructure, minimize downtime, and ensure the uninterrupted delivery of critical services.